Mueez Khan

My Experience as a Summer Intern at Rearc
An overview of the main projects and achievements I've accomplished during
my summer 2022 internship.
Published: 2022-10-13
Last updated: 2024-01-17
work
infrastructure-engineering
data-engineering
python
aws
terraform
cloud
sql
databricks
Note: This is a repost of this blog post on Rearc's company blog.
Introduction & Background
Hi, I'm Mueez Khan. I'm an undergraduate student majoring in Computer Science at Rutgers University (future update: graduated with a bachelor's degree!), and I was a remote summer intern at Rearc in the summer of 2022. In this article we'll go over various projects and achievements during my internship at Rearc.About Rearc
From Rearc's Linkedin page: Rearc is a boutique cloud software & services firm with engineers that have years of experience shaping the cloud journey of large scale enterprises. Our engineers are skilled at planning application migrations to the cloud and building cloud-native application environments and patterns for the future. We build strategic partnerships with our enterprise customers to enable long term success in the cloud.Rearc additionally provides data products on AWS Data Exchange (ADX) and Databricks with customers. Rearc is an Advanced Consulting Partner for the AWS Partner Network and a Databricks Technology Partner.
Data Platform Projects
My main projects during the internship involved working with Rearc's data platform infrastructure.Reducing AWS Costs with VPC Gateway Endpoints
One of the first tasks I completed was implementing a change that would lower AWS billing costs from the data platform's existing infrastructure. This data platform has jobs running on compute resources in a private subnet. These jobs may access data from public data sources or S3 buckets.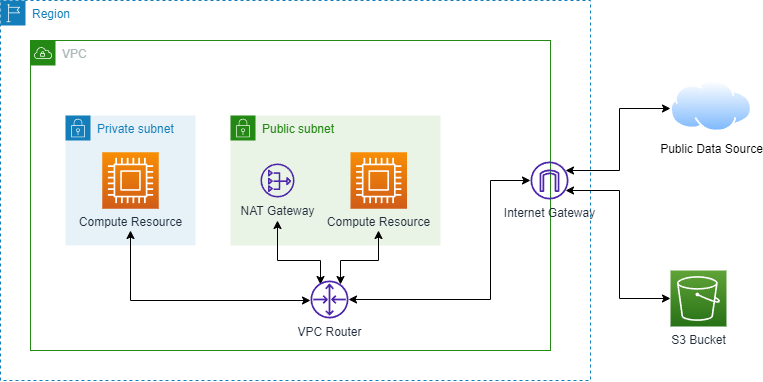 The architecture diagram above shows a sample initial architecture where a compute resource in a private subnet needs to access data sources from the public internet and S3 buckets. To access external data sources from the Internet, a NAT gateway is used. However, there are data processing charges for traffic that uses the NAT gateway.
The architecture diagram above shows a sample initial architecture where a compute resource in a private subnet needs to access data sources from the public internet and S3 buckets. To access external data sources from the Internet, a NAT gateway is used. However, there are data processing charges for traffic that uses the NAT gateway.
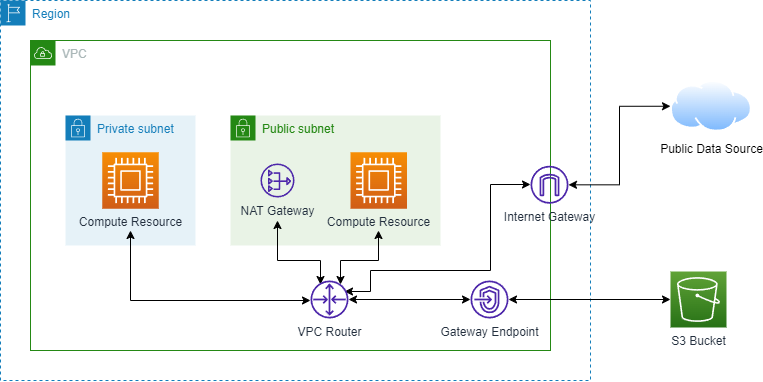 To reduce overall charges with our infrastructure, we are able to implement a VPC gateway endpoint. This endpoint allows our compute resources in the private subnet to access data from S3 buckets without going through a NAT gateway. The architecture still has a NAT gateway in case our compute resources need to access public data sources other than S3. Therefore, I worked on adding a VPC gateway endpoint resource to the data platform's infrastructure.
The data platform is built using AWS Cloud Development Kit (AWS CDK), an infrastructure-as-code (IaC) framework. However, my initial attempt involved creating an endpoint resource using Terraform (another IaC framework) and converting that to AWS CDK code. I started my attempt this way in order to explore whether engineers would be able to write custom Terraform modules and automatically integrate them into the existing AWS CDK infrastructure. I quickly learned that the conversion from Terraform to AWS CDK is not currently supported, and I actually converted my Terraform code to CDK for Terraform (CDKTF) code which is a completely different CDK than AWS CDK, despite the similarity in name.
I implemented the VPC gateway endpoint using AWS CDK and successfully added the VPC gateway endpoint to Rearc's data platform.
To reduce overall charges with our infrastructure, we are able to implement a VPC gateway endpoint. This endpoint allows our compute resources in the private subnet to access data from S3 buckets without going through a NAT gateway. The architecture still has a NAT gateway in case our compute resources need to access public data sources other than S3. Therefore, I worked on adding a VPC gateway endpoint resource to the data platform's infrastructure.
The data platform is built using AWS Cloud Development Kit (AWS CDK), an infrastructure-as-code (IaC) framework. However, my initial attempt involved creating an endpoint resource using Terraform (another IaC framework) and converting that to AWS CDK code. I started my attempt this way in order to explore whether engineers would be able to write custom Terraform modules and automatically integrate them into the existing AWS CDK infrastructure. I quickly learned that the conversion from Terraform to AWS CDK is not currently supported, and I actually converted my Terraform code to CDK for Terraform (CDKTF) code which is a completely different CDK than AWS CDK, despite the similarity in name.
I implemented the VPC gateway endpoint using AWS CDK and successfully added the VPC gateway endpoint to Rearc's data platform.
Verifying Endpoint Usage with VPC Flow Logs
Once the VPC gateway endpoint had been added, there was still the need to verify that the changes actually worked. To this end, I implemented a solution of enabling VPC flow logs which published to CloudWatch logs. With this implementation, we could analyze the IP traffic between the data platform's compute resources and the VPC gateway endpoint to ensure that traffic involving S3 works as expected. As with the VPC endpoint, I implemented the VPC flow logs using AWS CDK and had them publish to a CloudWatch log group which could be analyzed with CloudWatch Log Insights. Further details on implementing VPC flow logs using AWS CDK, their benefits, and gathering insights can be found from my first technical publication on Rearc's engineering blog.Building a Data Pipeline for VPC Flow Log Insights
Enabling VPC flow logs led to my final main project, which is building a data pipeline. I wanted to build a customizable pipeline to visualize insights from flow log data and use the Databricks Lakehouse Platform for its Databricks Notebook feature.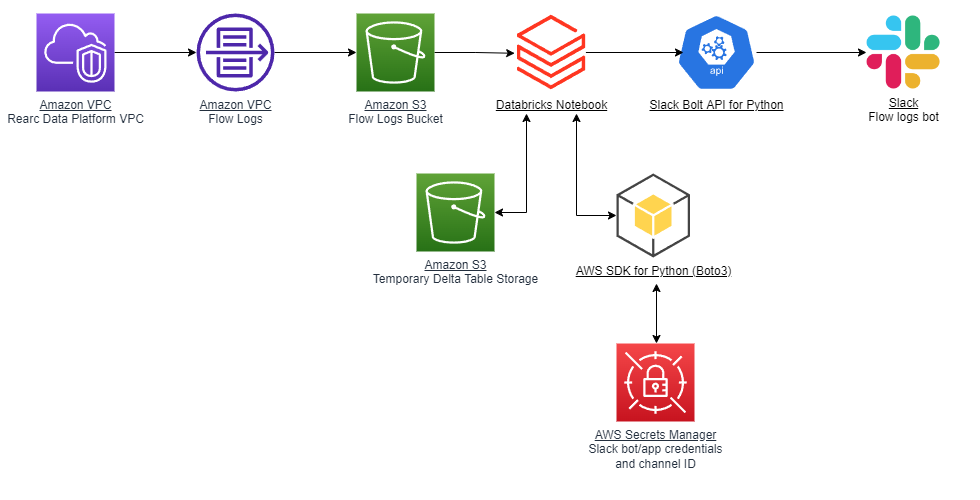 The architecture diagram above describes my final major project. The goal is to take VPC flow logs from Rearc's data platform, run SQL queries against the data for making visualizations, and send the visualizations to a Slack channel using a Slack bot. This data analysis would run on a daily basis to send insights from the previous day's flow logs.
Here's a high-level overview of the steps involved in the pipeline:
The architecture diagram above describes my final major project. The goal is to take VPC flow logs from Rearc's data platform, run SQL queries against the data for making visualizations, and send the visualizations to a Slack channel using a Slack bot. This data analysis would run on a daily basis to send insights from the previous day's flow logs.
Here's a high-level overview of the steps involved in the pipeline:
- VPC flow logs that contain IP traffic data are generated from Rearc's data platform VPC which has running data jobs
- Flow logs are published to an S3 bucket as
.parquetfiles (implemented using AWS CDK) - Data is ingested from the flow logs bucket to a Databricks Notebook (similar to a Jupyter Notebook) which is scheduled to run daily
- Flow logs data from the previous day is added to a temporary Delta table for running fast SQL queries and generating visualizations
- The AWS SDK for Python (Boto3) is used for retrieving the Slack app's credentials and channel ID from AWS Secrets Manager
- The Slack Bolt API for Python sends the data analysis and visualizations as a single message and thread to a specific Slack channel
Achievements
Technical Publication
Monitor AWS Network Traffic with VPC Flow Logs using Cloudwatch and AWS CDK is my first work-related technical publication. It helped refine my technical writing skills.Accreditations and Certification
I received several accreditations and a certification during the internship:
- AWS Partner: Cloud Economics Accreditation
- AWS Partner: Technical Accreditation
- Databricks Accredited Lakehouse Fundamentals
- AWS Certified Solutions Architect - Associate